241101 - Instalacja lokalnego LLM
Spis Treści #
- 1 - Co robimy
- 2 - Instalacja Ollama
- 3 - Python
- 4 - Wyjaśnienie kodu
- 5 - Zmieńmy Phi-3 na Bielik (lub dowolny inny model)
- 6 - Wartościowe linki powiązane
1. Co robimy #
- Instalujemy i odpalamy lokalny LLM używając Ollama
- SLM Microsoft Phi 3 (świetny, działa na każdej maszynie)
- Polski Bielik (działa nawet na RTX 2070)
- Piszemy "Hello World"
2. Instalacja Ollama #
2.1. Po co #
Ollama jest aplikacją, która pozwala na:
- ściągnięcie modelu lokalnie
- odpalenie lokalnego modelu
Działa na Windowsie, Macu i Linuksie. Ja będę robił instrukcję dla Linuksa, ale na YT widziałem sprawny tutorial jak to robić na Win.
2.2. Instalacja Ollama + sprawdzenie czy działa #
2.2.1. Jedyny fragment unikalny dla PopOS #
Na PopOs po prostu wpisz instrukcję w terminal:
curl -fsSL https://ollama.com/install.sh | sh2.2.2. Alternatywa jak masz Windowsa #
Ten link powinien pomóc. Ostrzegam, nie sprawdzałem, ale wygląda wiarygodnie (ściągnij exe, odpal exe).
2.2.3. Sprawdźmy czy Ollama działa #
Ściągnijmy i odpalmy model phi-3 (bardzo mały i bardzo przyjazny):
ollama run phi3:miniWpierw ściągnie model, potem go uruchomi i możecie z nim rozmawiać.
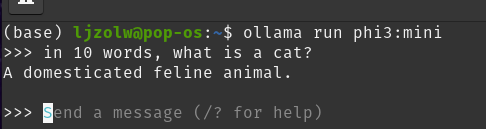
Można też sprawdzić, czy da się połączyć z poziomu API:
curl http://127.0.0.1:11434/api/generate -d '{
"model": "phi3:mini",
"prompt": "<|system|>You are an AI assistant.<|end|><|user|>What is a cat, in 1 paragraph?<|end|><|assistant|>",
"stream": false
}'
Co ważne, nie trzeba odpalać ollama run by to działało. Sam fakt posiadania modelu i zainstalowanego ollama sprawia, że to zadziała (na Linuksie).
2.3. Conda, tworzymy środowisko i przygotowujemy wszystko #
Ja używam PyCharm Community edition, ale działa w VS Code, terminalu, whatever.
Wpierw robimy nowe środowisko na conda (jeśli macie ComfyUI, macie conda):
conda create --name ollama python=3.13
conda activate ollama3. Python #
3.1. Tworzymy prosty kod klienta tekstowego #
Teraz stwórzmy prosty plik pythonowy; u mnie nazywa się 001-LocalPhiInit.py .
Kod wygląda taK:
import openai
client = openai.OpenAI(
base_url="http://localhost:11434/v1",
api_key="nokeyneeded",
)
def run_model(model_name, system_message):
messages = [
{"role": "system", "content": system_message},
]
while True:
question = input("\nYour question: ")
print("Sending question...")
messages.append({"role": "user", "content": question})
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=1,
max_tokens=400
)
bot_response = response.choices[0].message.content
messages.append({"role": "assistant", "content": bot_response})
print("Answer: ")
print(bot_response)
llm_model = {
"model": "phi3:mini",
"system_message": "You are a chat assistant that helps people with their questions."
}
run_model(llm_model["model"], llm_model["system_message"])3.2. Instalujemy zależności (dependencies) #
pip install openai- pamiętajcie, by być w odpowiednim środowisku condy ("ollama" u mnie)
3.3. Uruchomienie aplikacji #
python 001-LocalPhiInit.pyWynik (i co może pójść nie tak):
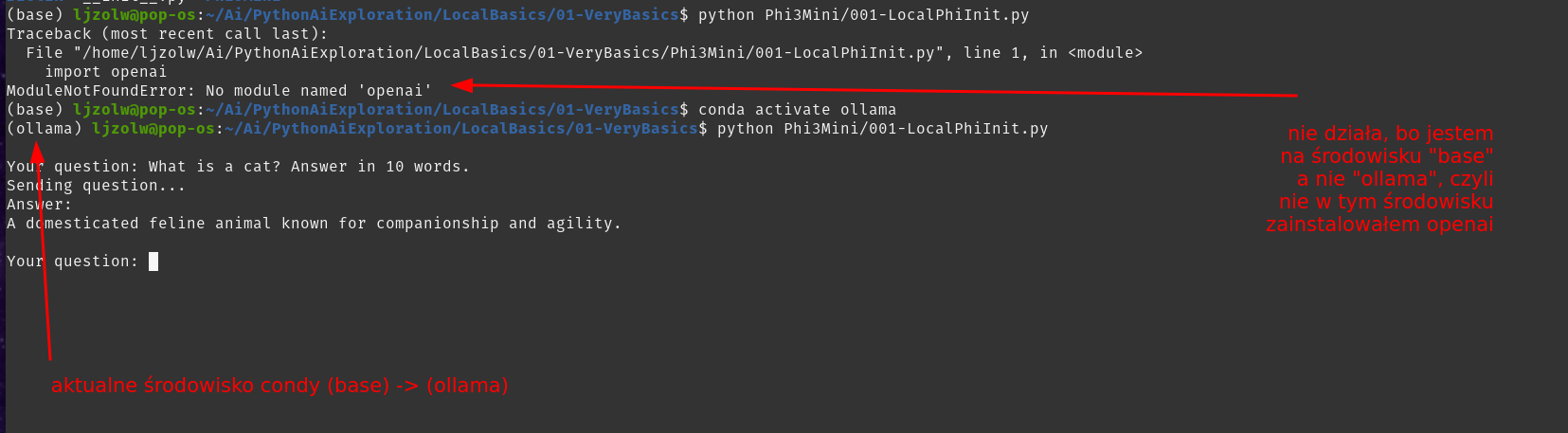
That's it, macie aktywnego LLMa :-)
4. Wyjaśnienie kodu #
W skrócie:
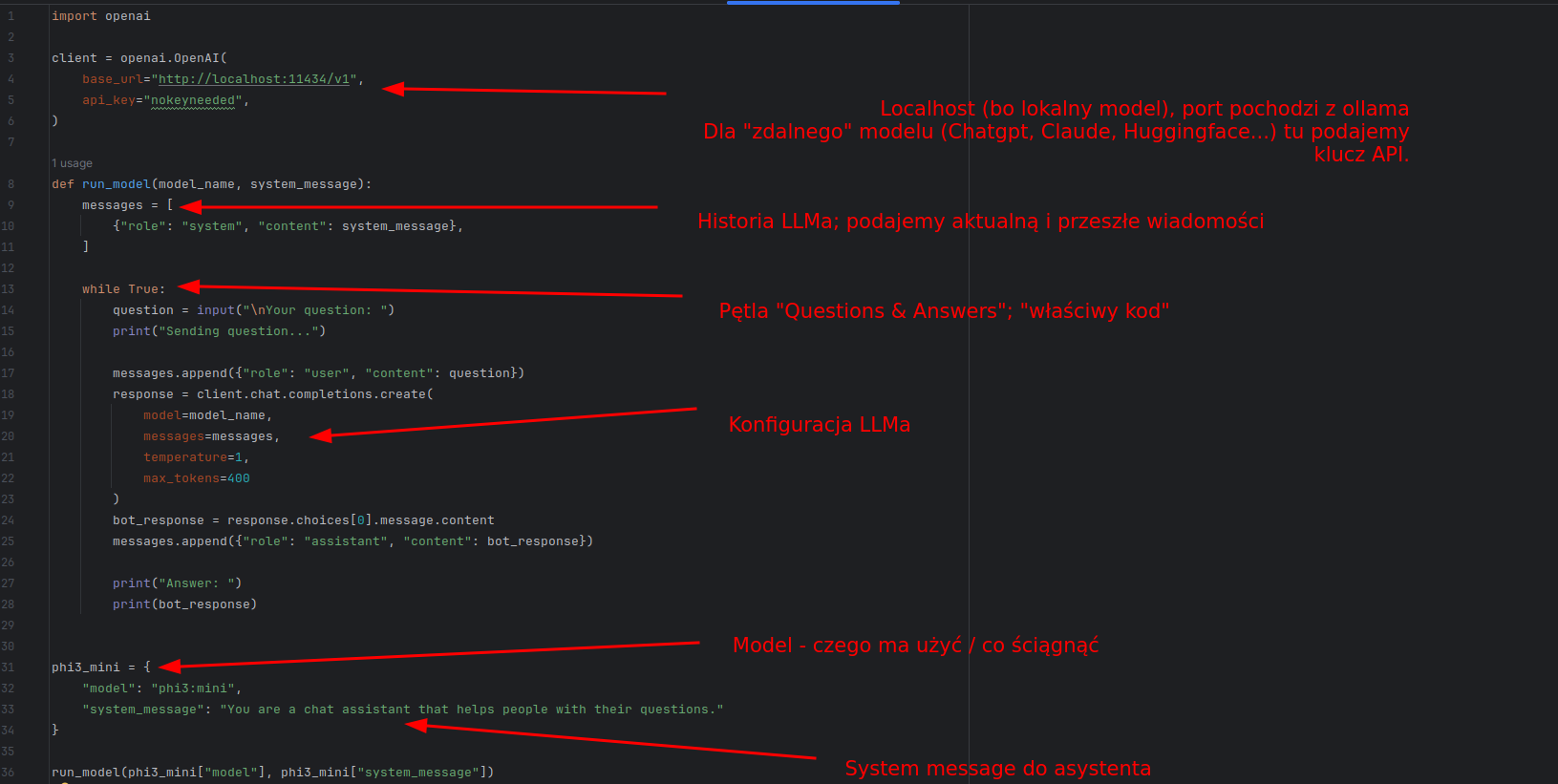
Jest to najprostszy sposób w jaki możemy postawić model lokalny.
5. Zmieńmy Phi-3 na Bielik (lub dowolny inny model) #
Bielik jest świetnym polskim modelem opartym o Mixtral; wykorzystywany jest komercyjnie i działa naprawdę dobrze.
Tak czy inaczej, trzeba tylko zmienić nazwę modelu i system message. Moja kopia Bielika to wersja Q4; dużo słabsza niż może pójść na lepszej karcie graficznej. Stąd używam "SpeakLeash/bielik-11b-v2.3-instruct:Q4_K_M"; słabszą wersję Bielika niż można wykorzystać (detale podaję w linkach).
llm_model = {
"model": "SpeakLeash/bielik-11b-v2.3-instruct:Q4_K_M",
"system_message": "Jesteś asystentem, który odpowiada krótko i zwięźle na pytania w języku polskim."
}Tak samo zadziała.

Dla porównania, zobaczcie co się stanie gdy zadam to pytanie po polsku do modelu Phi-3:

So yeah...
6. Wartościowe linki powiązane #
- https://github.com/microsoft/Phi-3CookBook/blob/main/md/01.Introduce/EnvironmentSetup.md
- Doskonała lista zasobów do Microsoft Phi. Cookbook, co da się zrobić...
- https://github.com/speakleash/Bielik-how-to-start/blob/main/Bielik_2_Ollama_integration.ipynb
- Repozytorium "co się da zrobić na Bieliku"