241102 - Embeddingi
Spis Treści #
- 1 - Co tu zrobimy
- 2 - Co to są embeddingi
- 3 - Embedding angielskiego tekstu do ChromaDb
- 3.1 - Uruchomienie środowiska
- 3.2 - Zacznijmy od danych
- 3.3 - Mamy dane. Trzeba je pociąć na kawałki
- 3.4 - Mamy pocięte dane. Trzeba je embedować w ChromaDb
- 3.4.1 - Co i czemu robimy
- 3.4.2 - Jak to robimy
- 3.4.2.1 - Wyjaśnienie początku
- 3.4.2.2 - Dodajemy ChromaDb
- 3.4.2.3 - Potencjalny problem z instalacją ChromaDb
- 3.4.2.4 - Embedujemy tekst
- 3.5 - Mamy vectorstore. Zróbmy query
- 4 - Całość kodu
- 5 - Wartościowe linki powiązane
1. Co tu zrobimy #
Dość naiwna, ale wystarczająca implementacja chunkingu i retrievalu semantycznie podobnych rzeczy
- Postawimy ChromaDB (in-memory)
- Zbudujemy customową funkcję embeddingową (bo użyjemy modelu do polskich embeddingów 'silver-retriever')
- Dodamy 3 artykuły do ChromaDB używając spaCy, z dzieleniem po zdaniach
- Zadamy parę pytań i wyciągniemy "najbardziej podobne frazy tekstu".
2. Co to są embeddingi #
Jednym zdaniem, wektorowa reprezentacja tekstu. Pod tym artykułem z Marqo.ai (popatrzcie na rysunki i diagramy) jest świetny opis krok po kroku. A naprawdę najlepszy imo link o embeddingach to ten Simona Willisona .
Nasz pierwszy cel - embedding tekstu do ChromaDb (bazy wektorowej)
3. Embedding angielskiego tekstu do ChromaDb #
3.1. Uruchomienie środowiska #
Zacznijmy od tego, że jesteśmy na odpowiednim środowisku, które już zrobiliśmy ostatnio:
conda activate ollamaJeśli używacie VS Code, to powyżej odpalacie w terminalu. Jeśli używacie PyCharm, klikacie tutaj:
A potem ustawiacie to tu:
Ok. Niezależnie od okoliczności, macie plik z takim kodem. Który to plik, jak się łatwo domyśleć, nic nie robi. U mnie ten plik nazywa się 003-Embeddings.py:
def run():
pass
run()3.2. Zacznijmy od danych #
3.2.1. Co i czemu robimy #
Embedding będzie potrzebował danych (do embedowania). Na potrzeby przykładu wykorzystajmy najlepszą stronę internetową na świecie, czyli bestmotherfucking.website/.
Musimy tą stronę ściągnąć i przekształcić w tekst. Z uwagi na to co najbardziej lubię w życiu, w formacie markdown:
# Nasz jedyny plik: 003-Embeddings.py
def run():
content = _url_to_markdown('https://bestmotherfucking.website')
print(content[0:100]) # Wyświetl pierwsze 100 znaków jako dowód pracy
pass
def _url_to_markdown(url: str):
return "placeholder" # Tu będziemy pracować; normalnie wydzieliłbym do innego pliku
run()3.2.2. Jak to robimy #
Do tego służą:
- pythonowa biblioteka
requestspozwoli nam odczytać stronę - pythonowa biblioteka
html2textpozwoli nam przekształcić html w markdown- tak się składa, że 80% interesujących mnie danych mam w markdown, więc...
Wynik:
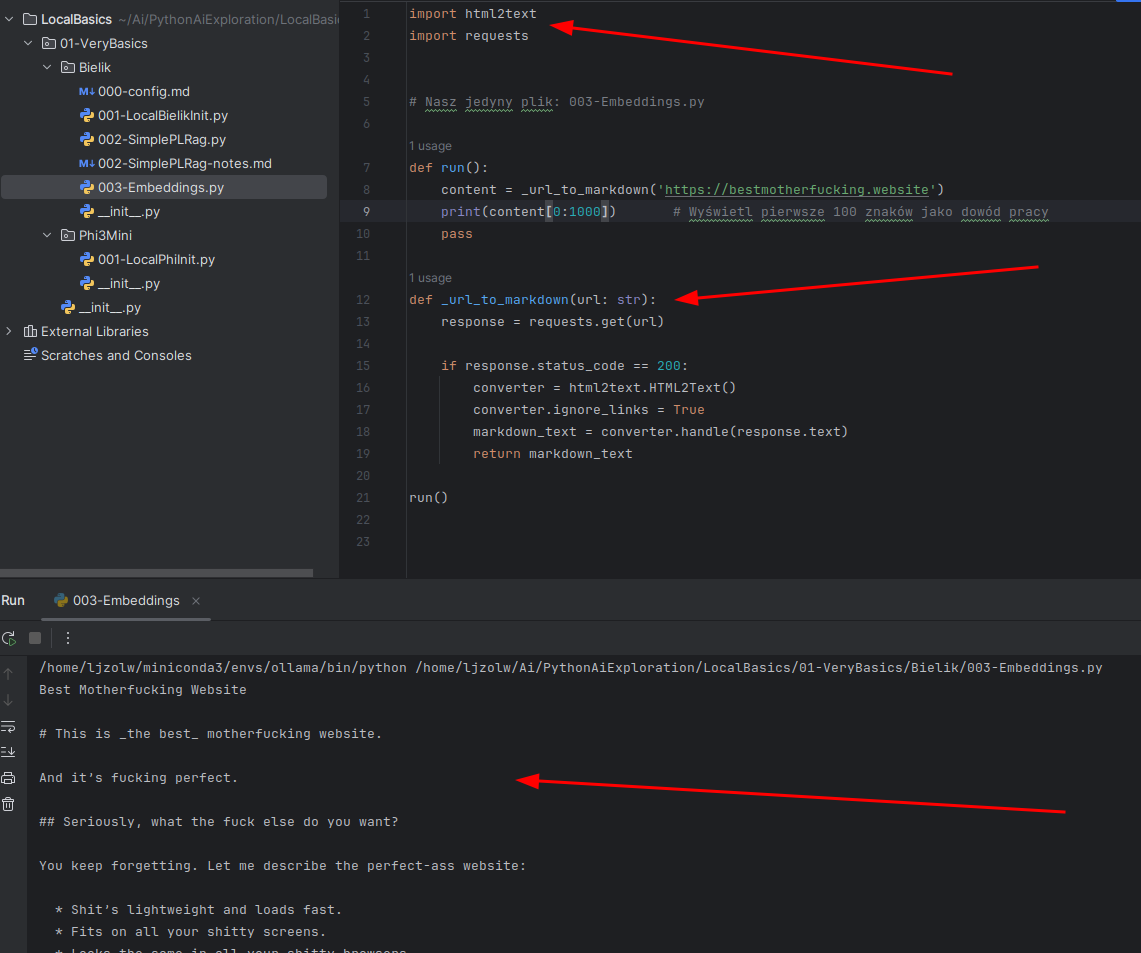
Kod do tego służący:
def _url_to_markdown(url: str):
response = requests.get(url)
if response.status_code == 200:
converter = html2text.HTML2Text()
converter.ignore_links = True
markdown_text = converter.handle(response.text)
return markdown_text3.3. Mamy dane. Trzeba je pociąć na kawałki #
3.3.1. Co i czemu robimy #
Załóżmy, że szukacie informacji o tym, ile kosztuje comiesięczna subskrybcja czegoś. Dużo lepiej dostać odpowiedź w stylu "20 $/miesiąc" niż 300 zdań tekstu, w którym ukryta jest informacja "20$/miesiąc".
Ale jednocześnie jeśli podzielimy tekst na zbyt małe kawałki tekstu, możemy zgubić istotny kontekst. Popatrzcie na taki przykład: "Andrzej jest rasistą. A przynajmniej tak pomyślałby ktoś, kto uwierzy w to, co o nim mówi była żona." Jeśli byśmy dzielili jedynie po ZDANIACH, zgubimy kluczową informację, że "była żona Andrzeja mówi, że ów jest rasistą" i zostalibyśmy z informacją "Andrzej jest rasistą". Nieco niefortunne.
Więc:
- Im większe mamy kawałki tekstu
- tym więcej pracy konsument tekstu (osoba czytająca, LLM...) potrzebuje do odnalezienia kluczowej informacji
- tym łatwiej konsumentowi tekstu się pogubić
- Im mniejsze mamy kawałki tekstu
- tym większa szansa na zgubienie kluczowej informacji i otrzymanie pewnych przekłamań
Jak spojrzycie na strukturę strony którą tniemy na kawałki, ma tekst dobrze pogrupowany nagłówkami. Możemy pociąć tekst przy użyciu nagłówków, o tak:
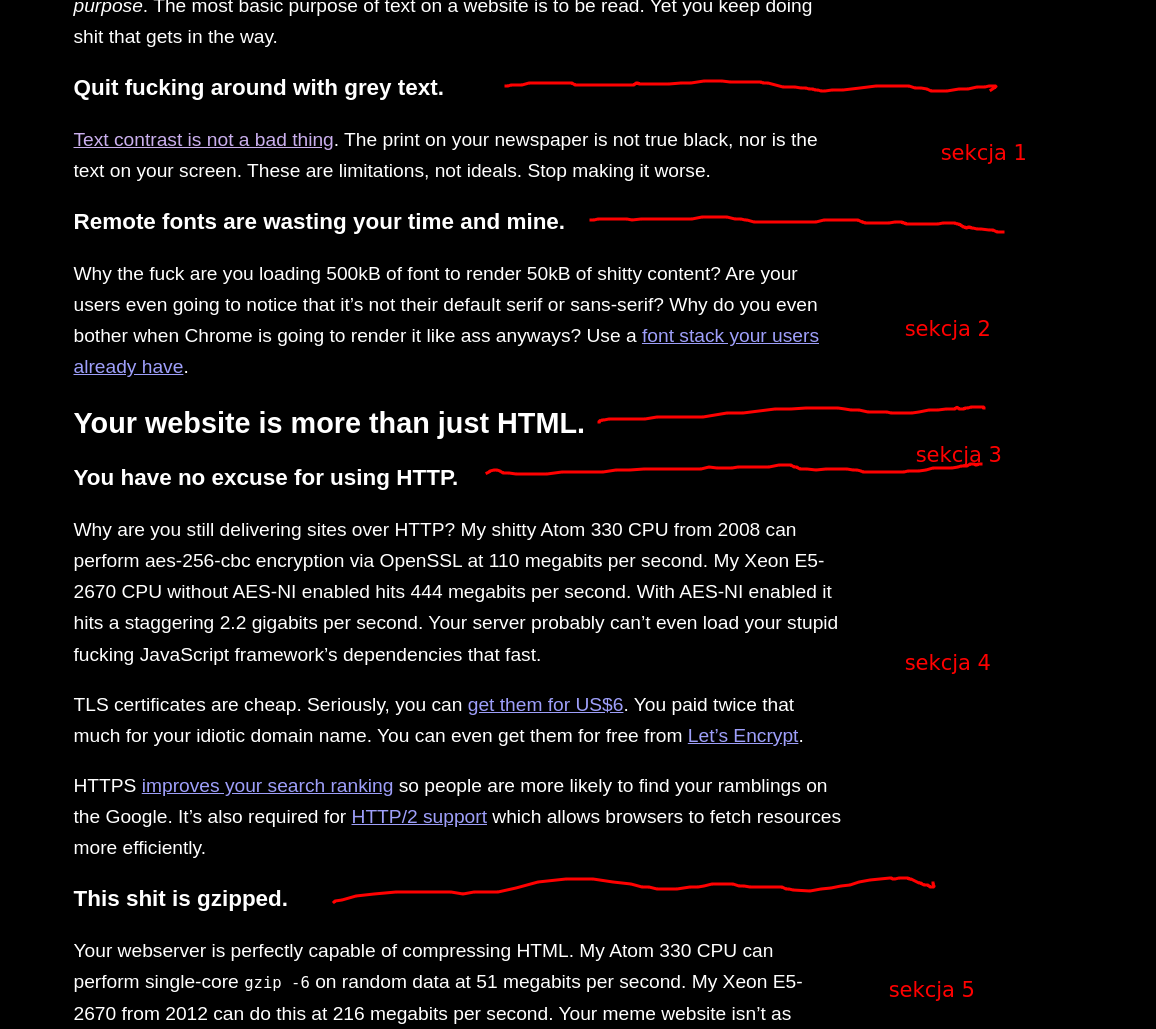
Nie jest to jedyny sposób i nie jest idealny, ale na nasze potrzeby wystarczy:
- przy celu jaki chcemy osiągnąć
- przy strukturze danych, jakie mamy
3.3.2. Jak to robimy #
Zaczynamy od tego:
def run():
content = _url_to_markdown('https://bestmotherfucking.website')
sections = _cut_into_sections(content)
pass
def _cut_into_sections(text: str) -> list[str]:
passNajwiększą zaletą dobrze zrobionego dokumentu markdownowego jest to, że można go naiwnie bardzo łatwo podzielić na nagłówki używając wyrażeń regularnych (regexów). Tak, tracimy niektóre informacje (np. nagłówki h3 zwykle są powiązane z obejmującym je h2), ale na potrzeby tego przykładu nie ma to aż takiego znaczenia. Plus, te konkretne dane tego nie wymagają.
Po napisaniu kodu dostaniemy coś takiego:
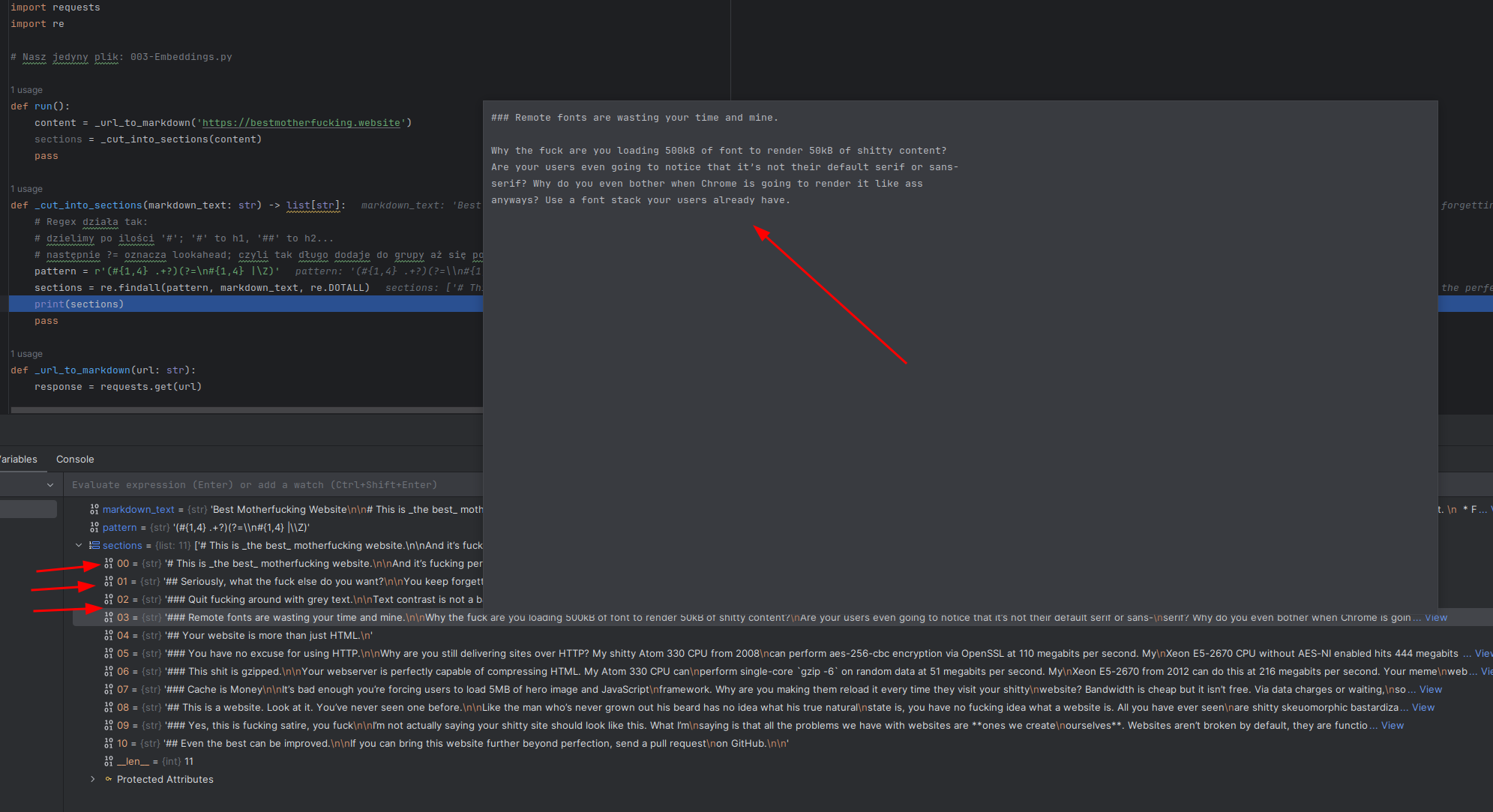
Z perspektywy kodu wygląda to tak (nie zapomnijcie na samą górę przenieść import re ):
import re
# Ten regex działa tak:
# dzielimy po h1-h4 ('#' - '####'); '#' to h1, '##' to h2...
# następnie ?= oznacza lookahead; czyli tak długo dodaje do grupy którą dzieli aż się pojawi kolejny nagłówek lub \Z, czyli koniec pliku / tekstu
def _cut_into_sections(markdown_text: str) -> list[str]:
pattern = r'(#{1,4} .+?)(?=\n#{1,4} |\Z)'
sections = re.findall(pattern, markdown_text, re.DOTALL)
return sections3.4. Mamy pocięte dane. Trzeba je embedować w ChromaDb #
3.4.1. Co i czemu robimy #
ChromaDb to vectorstore. Baza wektorowa. Coś, co jeśli wpiszę "why should css have high contrast" zwróci mi odpowiednią sekcję z bestmotherfucking.website. Coś, co "przeszukujesz językiem naturalnym" i wykorzystuje zasadę bliskości podobnych wektorów by dać nam najbardziej podobny tekst.
Robimy to po to, by móc przeszukiwać dane / stronę :-).
Więc co konkretnie zrobimy:
- Dodamy ChromaDb do naszej aplikacji
- Przekształcimy tekst w embeddingi używając mechanizmów ChromaDb
3.4.2. Jak to robimy #
3.4.2.1. Wyjaśnienie początku
Zaczynamy od kodu:
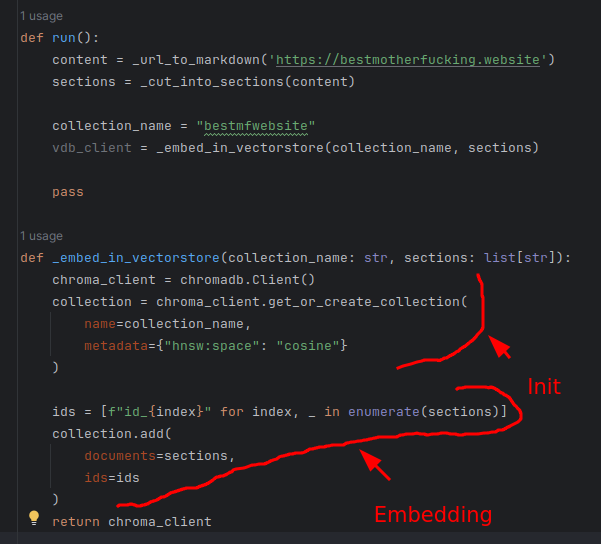
def run():
content = _url_to_markdown('https://bestmotherfucking.website')
sections = _cut_into_sections(content)
collection_name = "bestmfwebsite"
vdb_client = _embed_in_vectorstore(collection_name, sections)
pass
def _embed_in_vectorstore(collection_name: str, sections: list[str]):
passI teraz kilka wyjaśnień:
- W bazie relacyjnej pracujemy na tablicach. Tu, w vectorstore pracujemy na kolekcjach.
- Dlatego podałem collection_name jako parametr; muszę wiedzieć przy robieniu query którą kolekcję odpytać.
- vdb_client to klient ChromaDb. Żeby móc robić na nim query, muszę go naturalnie zwrócić :-).
Oki, przejdźmy do konkretów, teraz nieco mniejszymi krokami.
3.4.2.2. Dodajemy ChromaDb
Kod:
import chromadb # oczywiście, ta linijka na samą górę pliku
def _embed_in_vectorstore(collection_name: str, sections: list[str]):
chroma_client = chromadb.Client()
collection = chroma_client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)Gdzie:
name=collection_name:- po to robiliśmy
collection_name. "Nazwa kolekcji". Po tym robimy potem query.
- po to robiliśmy
metadata={"hnsw:space": "cosine"}: funkcja sprawdzająca odległość pomiędzy wektorami- dla cosine '0' oznacza identyczne wektory a '1' maksymalnie rozbieżne wektory
- różne dane i różne funkcje embedujące (tekst -> embeddingi) lepiej działają z różnymi funkcjami odległości
3.4.2.3. Potencjalny problem z instalacją ChromaDb
Chwilowo (241102) rustowa paczka na której polega ChromaDb nie obsługuje python 3.13. To znaczy, że może być konieczność downgradowania środowiska conda ollama do 3.12. Jeśli macie ten problem:
conda activate ollama
conda install python=3.12Ja to zrobiłem, więc chwilowo działam na python 3.12.
Po zrobieniu tego poniższe kroki działają.
3.4.2.4. Embedujemy tekst
Znowu zacznijmy od kodu:
import chromadb # oczywiście, ta linijka na samą górę pliku
def _embed_in_vectorstore(collection_name: str, sections: list[str]):
chroma_client = chromadb.Client()
collection = chroma_client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
# NOWY KOD PONIŻEJ
ids = [f"id_{index}" for index, _ in enumerate(sections)]
collection.add(
documents=sections,
ids=ids
)
return chroma_clientWyjaśniam.
- Każdy rekord ChromaDb potrzebuje mieć indeks
- stąd kod
ids = [f"id_{index}" for index, _ in enumerate(sections)]- "zrób dla mnie listę indeksów odpowiadającą liście sekcji"
- stąd kod
- ChromaDb wymaga podania danych w formie pasujących do siebie list
- czyli tak:
- docs: ["pierwsza sekcja", "druga sekcja"...]
- ids: ["0", "1"...]
- dlatego podaję listę dokumentów i indeksów tak jak podaję.
- czyli tak:
Za pierwszym uruchomieniem ChromaDb może pobrać "domyślny model embeddingowy":
I fundamentalnie nasz kod w chwili obecnej wygląda tak:
3.5. Mamy vectorstore. Zróbmy query. #
3.5.1. Co i czemu robimy #
Chcemy zobaczyć, jak to fundamentalnie działa. Znaleźć "najbardziej podobne dane".
3.5.2. Jak to robimy #
Zacznijmy od kodu robienia query. To 3 ostatnie linijki:
def run():
content = _url_to_markdown('https://bestmotherfucking.website')
sections = _cut_into_sections(content)
collection_name = "bestmfwebsite"
vdb_client = _embed_in_vectorstore(collection_name, sections)
query = "Why are the websites not as good as they could be?" # podstawcie swoje query
collection = vdb_client.get_collection(collection_name)
results = collection.query(query_texts=[query], n_results=3)Jaką dostaniemy odpowiedź dla pytania Why are the websites not as good as they could be?:
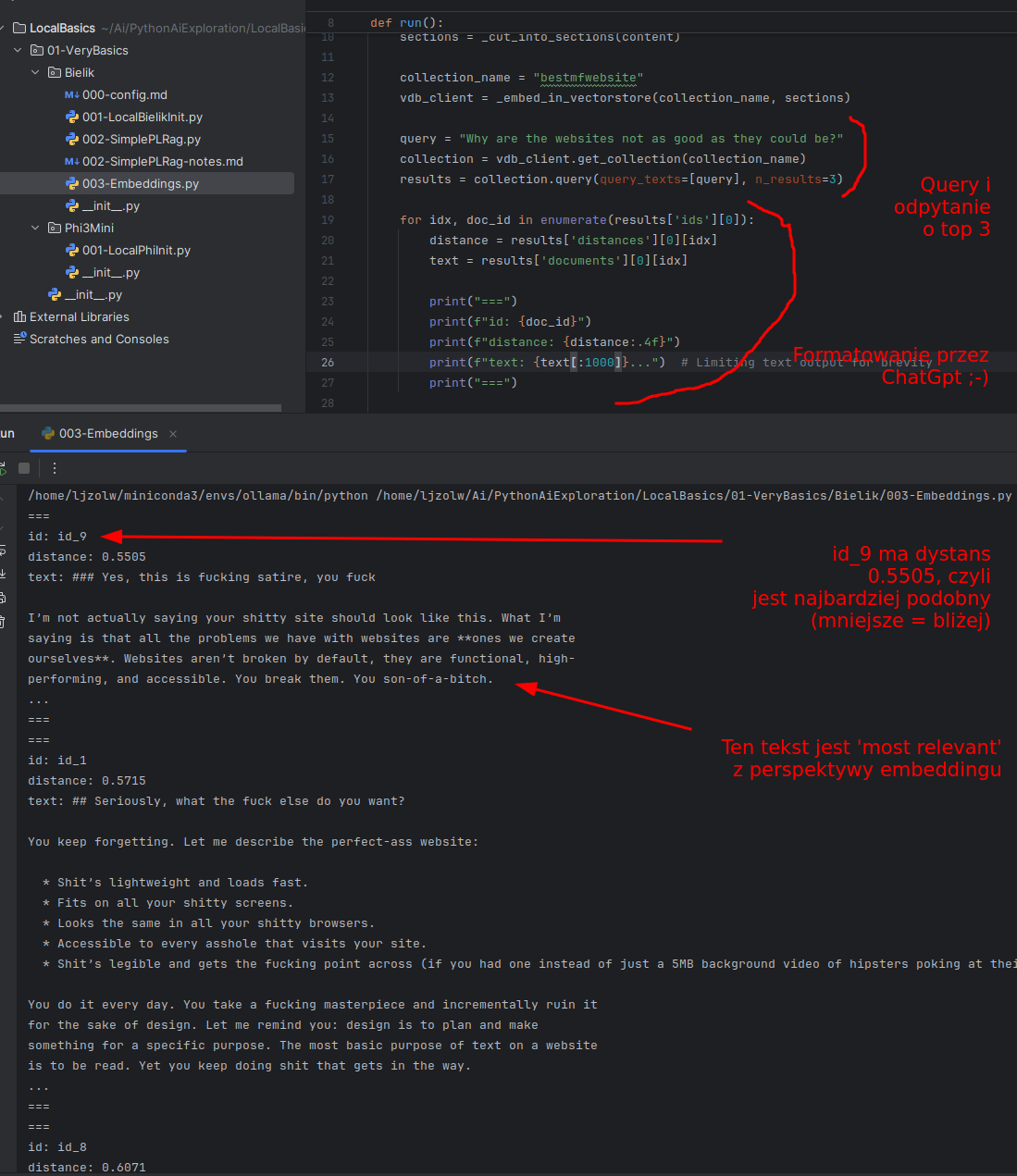
Oki. Na co tu warto zwrócić uwagę:
- Tu nie było żadnego keyworda.
- Twórca tej strony nie pisze "not as good", pisze "it sucks, you fuck".
- A jednak ChromaDb prawidłowo zwróciła najbardziej pasujący paragraf jako pierwszy.
- Odległości wektorowe są [0.5, 0.7]. To nie są duże różnice.
- Wynika to z tego, że porównujemy mały tekst z dużym tekstem.
- To wynika z naszego bardzo prymitywnego podejścia; moglibyśmy "powiększyć" query lub "embedować rdzeń tekstu" (wyciągnięty przez LLMa) i dodać całość sekcji jako metadane...
- (tu jest dużo sztuczek; dla każdego zestawu danych robimy to oczywiście inaczej)
- Z ciekawostek, trzy NAJGORSZE rezultaty jakie dostaliśmy to:
- distance: 0.7564, nagłówek: ### Remote fonts are wasting your time and mine.
- distance: 0.8178, nagłówek: ### This shit is gzipped.
- distance: distance: 0.8411, nagłówek: ### Quit fucking around with grey text.
- To zadziałało nawet dla "sparsowanej strony internetowej" i "domyślnego modelu embedującego"
- Im lepsze mamy dane, im lepiej pogrupowane, tym lepsza odpowiedź
- Dla języka polskiego odpowiedź byłaby dużo gorsza; tu używam silver_retriever (o tym w następnych dokumentach)
I teraz wystarczy output z ChromaDb podać do LLM jako kontekst i macie pierwszego prostego RAGa. Ale to w następnych dokumentach ;-).
4. Całość kodu #
import html2text
import requests
import re
import chromadb
# Nasz jedyny plik: 003-Embeddings.py
def run():
content = _url_to_markdown('https://bestmotherfucking.website')
sections = _cut_into_sections(content)
collection_name = "bestmfwebsite"
vdb_client = _embed_in_vectorstore(collection_name, sections)
query = "Why are the websites not as good as they could be?"
collection = vdb_client.get_collection(collection_name)
results = collection.query(query_texts=[query], n_results=20)
for idx, doc_id in enumerate(results['ids'][0]):
distance = results['distances'][0][idx]
text = results['documents'][0][idx]
print("===")
print(f"id: {doc_id}")
print(f"distance: {distance:.4f}")
print(f"text: {text[:1000]}...") # Limiting text output for brevity
print("===")
def _embed_in_vectorstore(collection_name: str, sections: list[str]):
chroma_client = chromadb.Client()
collection = chroma_client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
ids = [f"id_{index}" for index, _ in enumerate(sections)]
collection.add(
documents=sections,
ids=ids
)
return chroma_client
def _cut_into_sections(markdown_text: str) -> list[str]:
# Ten regex działa tak:
# dzielimy po h1-h4 ('#' - '####'); '#' to h1, '##' to h2...
# następnie ?= oznacza lookahead; czyli tak długo dodaje do grupy którą dzieli aż się pojawi kolejny nagłówek lub \Z, czyli koniec pliku / tekstu
pattern = r'(#{1,4} .+?)(?=\n#{1,4} |\Z)'
sections = re.findall(pattern, markdown_text, re.DOTALL)
return sections
def _url_to_markdown(url: str):
response = requests.get(url)
if response.status_code == 200:
converter = html2text.HTML2Text()
converter.ignore_links = True
markdown_text = converter.handle(response.text)
return markdown_text
run()5. Wartościowe linki powiązane #
- Simon Willison, best embeddings explanation ever
- best explanation ever
- https://www.marqo.ai/courses/fine-tuning-embedding-models
- Strona pokazująca czym są embeddingi, dokładnie wyjaśniająca rzeczy (zwłaszcza pierwsze 3-4 artykuły)