241104 - Dalsza zabawa z RAG
Spis Treści #
- 1 - Co tu zrobimy
- 2 - Od czego zaczynamy?
- 3 - Dodanie większej ilości materiałów
- 4 - Sprawdźmy inny model
- 5 - Inna strategia chunkowania (po zdaniach)
- 6 - Całość kodu wynikowego (skonfigurowany na sekcje)
- 7 - Wartościowe linki powiązane
1. Co tu zrobimy #
Kontynuujemy artykuł 241103-simple-rag.
- Dodajemy inne materiały do bazy wektorowej
- Zmieniamy LLM na inny
- Dodajemy inną strategię chunkowania
2. Od czego zaczynamy? #
Nie podaję żadnych funkcji pomocniczych (bo je macie); zacznijcie od poprzedniego dokumentu.
A jako kod - wychodzimy od tego (wszystkie funkcje macie):
def run():
# 1. Acquire content to query
content = _url_to_markdown('https://bestmotherfucking.website')
sections = _cut_into_sections(content)
# 2. Embed content in vectorstore
collection_name = "bestmfwebsite"
vdb_client = _embed_in_vectorstore(collection_name, sections)
# 3. Add local LLM
selected_llm = "phi3.5:3.8b-mini-instruct-q8_0"
system_message_for_llm = "<|system|>\nYou are a helpful and concise assistant answering questions."
messages = [{"role": "system", "content": system_message_for_llm }]
llm_client = openai.OpenAI(base_url="http://localhost:11434/v1", api_key="nokeyneeded")
# 4. Main application loop
while True:
# 4.1. Get user question and exit the application
user_question = input("What is your question?")
if user_question == "exit":
break
# 4.2. Extract data from knowledge base (vectorstore)
collection = vdb_client.get_collection(collection_name)
context = collection.query(query_texts=[user_question], n_results=5)
# 4.3. Build an appropriate prompt from the template, question and context
prompt = _create_prompt(user_question, context)
# 4.4. Pass prompt to LLM and get the answer
bot_response, messages = _query_llm(llm_client, selected_llm, messages, prompt)
# 4.5. Display answer
print(_format_answer_for_print(bot_response, context))3. Dodanie większej ilości materiałów #
3.1. Co i dlaczego #
Chcemy zobaczyć jak to działa dla większej ilości materiałów. Niestety, zdecydowana większość rzeczy które kiedykolwiek napisałem jest po polsku, więc... wykorzystamy kilka artykułów z internetu.
Są to dobre artykuły. Wczyta i sparsuje się 4/5 najpewniej.
3.2. Implementacja #
To jest to co robimy:
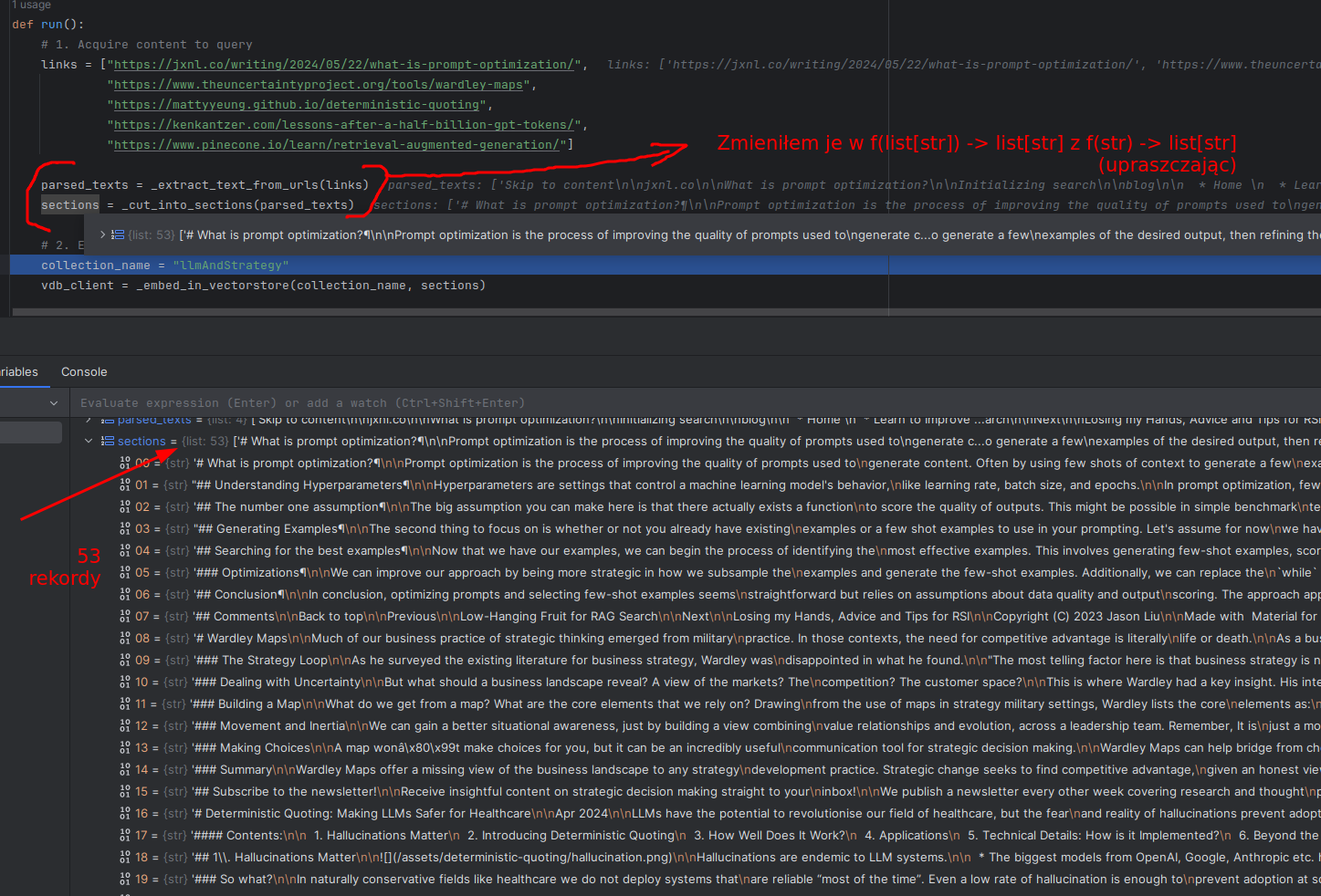
Z perspektywy kodu, zmieniamy całą sekcję "# 1. Acquire content to query" tak jak na rysunku powyżej. Jako, że chcemy dodać opcję zmiany strategii parsowania, wydzieliłem też funkcję "_extract_markdown_from_html" która była kiedyś elementem funkcji "_extract_text_from_urls" (która nazywała się "_url_to_markdown").
Czyli początek naszego pliku wygląda teraz tak:
def run():
# 1. Acquire content to query
links = ["https://jxnl.co/writing/2024/05/22/what-is-prompt-optimization/",
"https://www.theuncertaintyproject.org/tools/wardley-maps",
"https://mattyyeung.github.io/deterministic-quoting",
"https://kenkantzer.com/lessons-after-a-half-billion-gpt-tokens/",
"https://www.pinecone.io/learn/retrieval-augmented-generation/"]
parsed_texts = _extract_text_from_urls(links)
sections = _cut_into_sections(parsed_texts)
# 2. Embed content in vectorstore
collection_name = "llmAndStrategy"
vdb_client = _embed_in_vectorstore(collection_name, sections)A implementacja funkcji pomocniczych (po ich zmianach) wygląda tak (jak widzicie, zmieniłem praktycznie jedynie str -> list[str]):
def _cut_into_sections(markdown_texts: list[str]) -> list[str]:
all_sections = []
for markdown_text in markdown_texts:
# Ten regex działa tak:
# dzielimy po h1-h4 ('#' - '####'); '#' to h1, '##' to h2...
# następnie ?= oznacza lookahead; czyli tak długo dodaje do grupy którą dzieli aż się pojawi kolejny nagłówek lub \Z, czyli koniec pliku / tekstu
pattern = r'(#{1,4} .+?)(?=\n#{1,4} |\Z)'
sections = re.findall(pattern, markdown_text, re.DOTALL)
all_sections.extend(sections)
return all_sections
def _extract_text_from_urls(urls: list[str]) -> list[str]:
all_texts = []
for url in urls:
response = requests.get(url)
if response.status_code == 200:
text = _extract_markdown_from_html(response)
all_texts.append(text)
return all_texts
def _extract_markdown_from_html(response):
converter = html2text.HTML2Text()
converter.ignore_links = True
text = converter.handle(response.text)
return textReszta działa bez zmian:
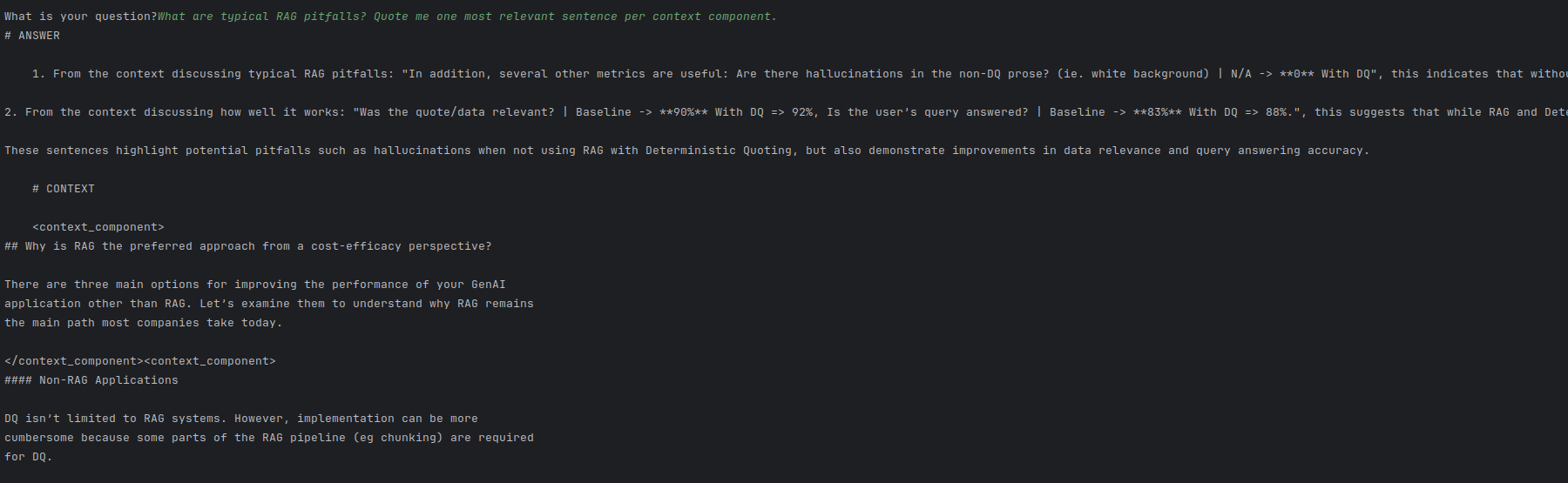
Oczywiście, można kwestionować jak dobrze działa - ale LLM odpowie tylko na podstawie tego, co dostanie na wejściu, fundamentalnie.
W kontekście RAG problem nie leży tu w "G" (generacja prawidłowej odpowiedzi) a w "R" (pozyskanie prawidłowych danych źródłowych). Jak większość problemów z RAGiem - dane wejściowe i przyciągnięcie właściwych danych. Potencjalnie mniejsze sekcje tekstu lub bardziej pasujące sekcje tekstu mogłyby tu pomóc. Może nie "top 5" a "top 10, ale mniejszych". Może dzielenie po markdownie jest tu suboptymalne.
Dla różnych query potrafił podać mniej lub bardziej wartościowe odpowiedzi, więc to nawet w tak prostej formie nadal działa. Acz nie można mu ufać, póki nie podamy źródeł do wyświetlania itp.
3.3. Obserwacje i wnioski #
W jednym z artykułów (akurat nie tym, który się sparsował) napisano wyraźnie:
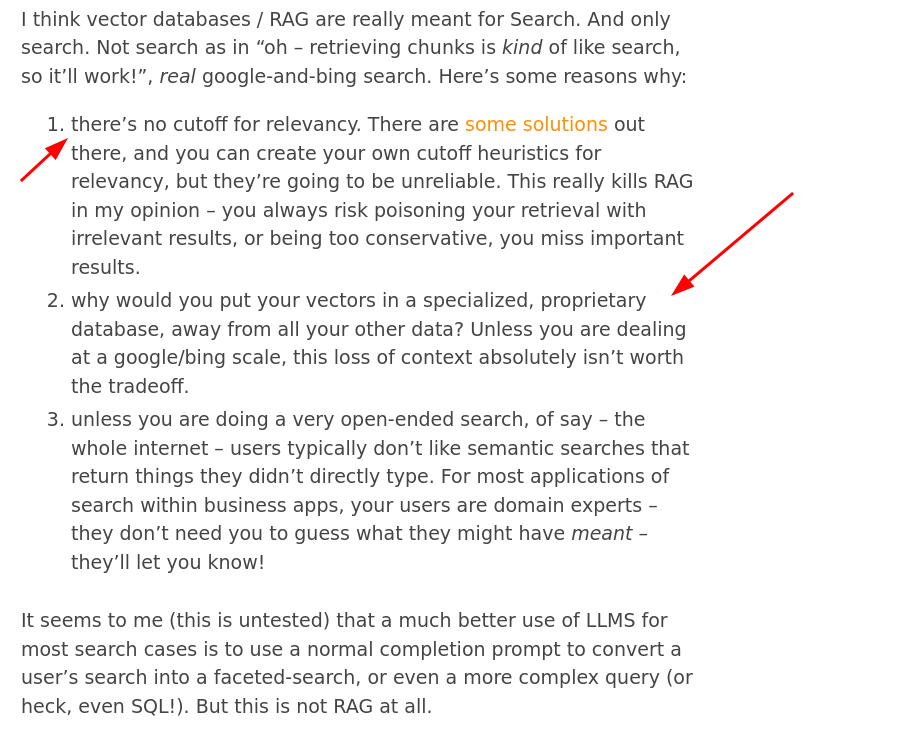
I wiecie co, autor ma trochę racji. Gdybym dobrze przygotował dane (tak jak przygotowałem je do systemu RPG), pociął rekordy do SQLite i wyciągał rekordy z SQLite jako dane regularne, miałbym dużo prościej. Jako przykład, mogę odpytać bazę danych o "wszystkie dokonania Arianny Verlen oraz wszystkie zasługi" i dostanę to od ręki w formie regularnej. Na podstawie tego mogę teraz poprosić o streszczenie historii życia Arianny Verlen i dostanę całkiem sensowny układ.
Jeśli nie umiem napisać tych zapytań SQLowych, mogę użyć LLMa który zrobi to dla mnie.
Ale to nadal jest RAG. Wyciągnięcie danych ze źródła danych i podanie wyniku do LLMa, by coś z tym zrobił.
Ale nie uważam, że semantyczny search jest błędem. Można np. pociąć nie po paragrafach a po zdaniach (lub trzyzdaniowych strukturach) i w metadanych zapisać "otoczenie" (czy jako markdownowy paragraf czy jako np. 300 znaków wcześniej i 300 później). Dzięki temu mamy porównywanie po zdaniach (krótki tekst do krótkiego tekstu, wyższe podobieństwo) a do LLMa może pójść "otoczenie" jako większa całość.
Tu jest dużo rzeczy do sprawdzenia i niestety każdy zbiór danych będzie mieć inną odpowiedź.
4. Sprawdźmy inny model #
4.1. Implementacja #
Wybieram model Gemma2, 9 mln parametrów.
ollama pull gemma2:9bW kodzie zmieniamy jedną linijkę:
selected_llm = "gemma2:9b"Niestety, nie wiem ile ma max. tokenów wejściowych; to może być główny problem przy aplikacji typu RAG (która korzysta z upiornej ilości tokenów na wejściu). Tak samo nie wiem w jakim stylu się komunikować z tym modelem, więc podmiana bezpośrednia może nie dać tak dobrego efektu jak mogłoby być.
4.2. Wynik i obserwacje #
Popatrzmy na wynik:
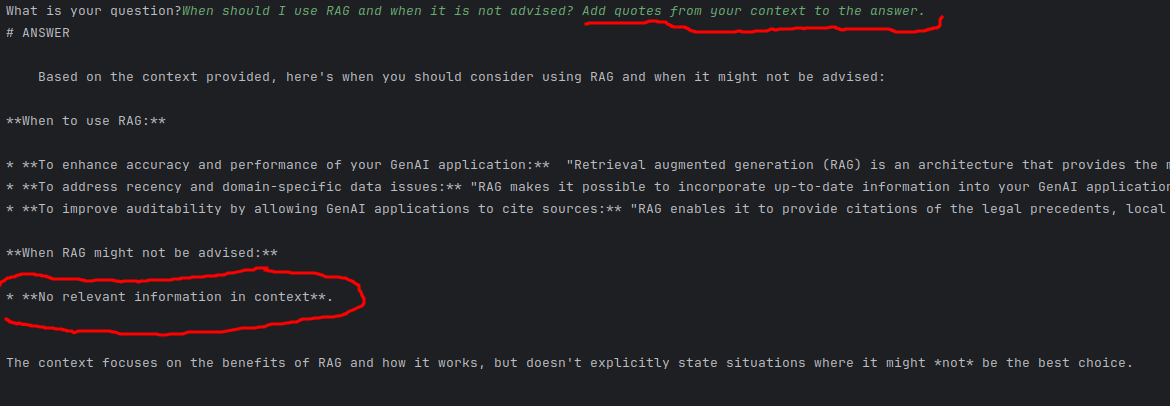
Teraz; odpowiedź, w której nie podkreśliłem tekstu na czerwono była jeszcze lepsza i lepiej ustrukturyzowana. Ale wkleiłem tą odpowiedź, bo jest tu coś ważnego.
- WŁAŚNIE TO CO PODKREŚLIŁEM obniża jakość Retrievera.
- Z perspektywy "bliskości wektorów" Retriever:
- nie skupia się tylko na pierwszym zdaniu mojego pytania ("When should I use RAG and when it is not advised?")
- ale też drugiego członu ("Quote me most important sentences from the relevant context you are using.").
- -> To powoduje, że przy takim zapytaniu odległość "idealnego" fragmentu tekstu będzie dalsza niż gdybym drugiej części nigdy nie napisał.
- Z perspektywy "bliskości wektorów" Retriever:
Można to oczywiście usunąć przez "preprocesor" LLM; pierwszy LLM który przerobi query (np. podzieli query na dwie części; część "do vectorstore only" i "część ogólną").
Faktycznie, w kontekście nie mamy informacji o tym "kiedy nie działa".
Dla porównania, odpowiedź bez tej drugiej części:
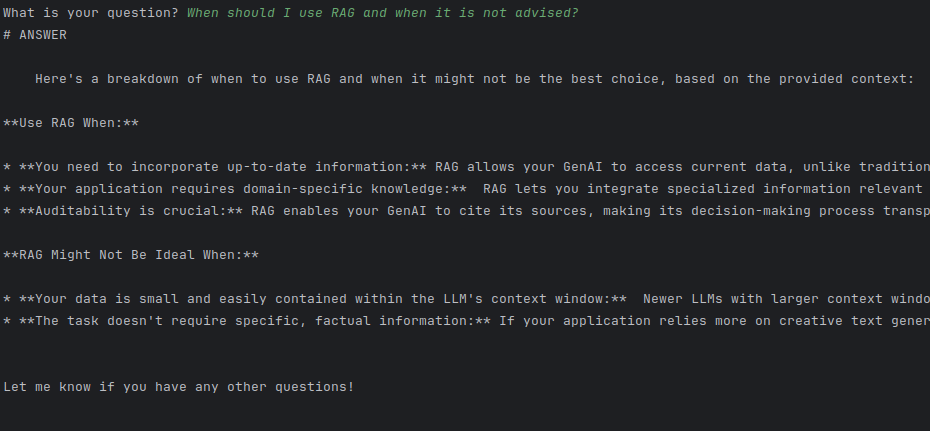
I tutaj podkreślenie na czerwono pokazuje wyraźnie, że przeczytał dokumenty kontekstu. Ale w kontekście nadal nie ma informacji o tym kiedy RAG nie jest warty używania. A jednak odpowiedział, zgodnie ze swoją wiedzą.
Wniosek
- zażądanie cytatów podniosło "odpowiedź zgodną z Kontekstem"
- ok, ale przy temperaturze 0.2 ma prawo trochę "myśleć" i rozumować; jakbym chciał to maksymalnie obniżyć, dałbym 0
- zażądanie cytatów - przez aktualną implementację - obniżyło trafność odpowiedzi z vectorstore.
- na razie mam mało dokumentów, ale pomyślcie co by było jakbym miał nie 53 sekcje a 9999 sekcji
- fundamentalnie? Różne dokumenty i prompty -> różne odpowiedzi.
Dla porównania, to samo na Phi-3:
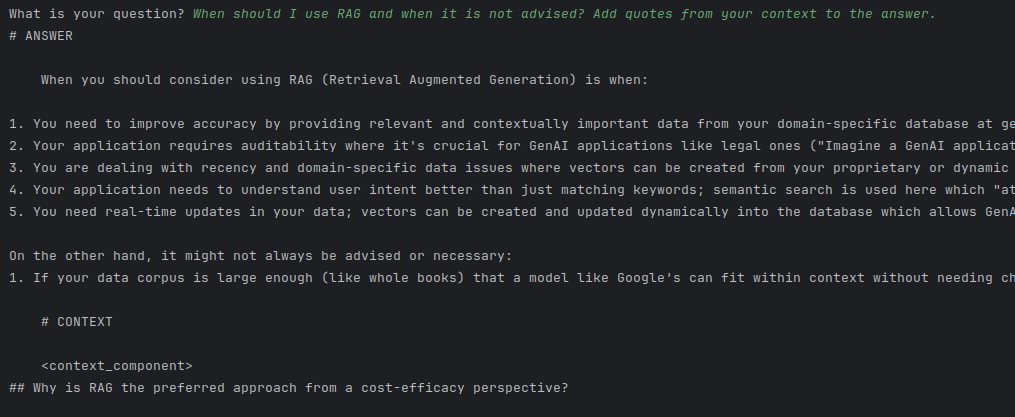
Jako, że nie widać dobrze, pokażę całość linijki jednej odpowiedzi:
- You need to improve accuracy by providing relevant and contextually important data from your domain-specific database at generation time, as stated in the text "RAG passes additional relevant content...at generation time."
I tym razem:
- Vectorstore znalazł "kiedy RAG jest niewskazany" w źródłach (jeśli context window jest odpowiednio duży)
- Phi-3 wyciągnął te informacje
Jak widzicie, Gemma oraz Phi-3 odpowiadają INACZEJ. I w różnych kontekstach różne modele będą optymalnymi rozwiązaniami. Ale oba dają radę; a jeszcze przecież można popracować z promptem, system message... takie rzeczy się kalibruje z czasem.
5. Inna strategia chunkowania (po zdaniach) #
5.1. Co i dlaczego #
W tej chwili robimy chunking po sekcjach. Typowy output (widok z debuggera):

Podajemy pięć najlepiej dopasowanych sekcji do LLM jako Retrieved Information. A każda wiadomość jaką podajemy "kosztuje" określoną ilość tokenów. Jako przykład, podałem ten tekst do policzenia przez OpenAi Tokenizer; nawet jeśli to nie jest DOKŁADNIE ten tokenizer, widać jak to działa i wygląda:
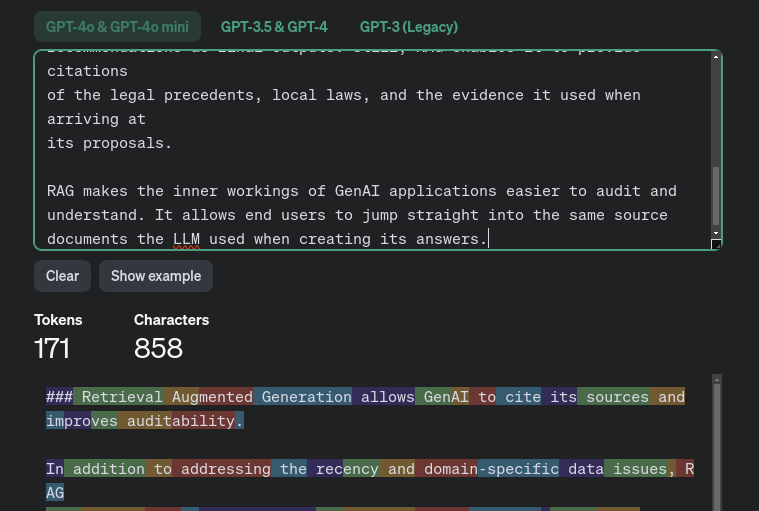
Czyli podajemy na wejściu 5 * 200 = 1000 tokenów samego kontekstu. Nie licząc prompta, query i wszystkich poprzednich wiadomości / historii konwersacji. Właśnie to jest powodem, czemu chcieliśmy mieć bardzo duże okno kontekstu na wejściu.
A teraz wyobraźmy sobie, że mamy dane wyglądające w taki sposób:

W tym momencie każdy rekord zawiera wszystkie potrzebne informacje, ale mamy tych rekordów bardzo dużo. Waga pojedynczego rekordu:
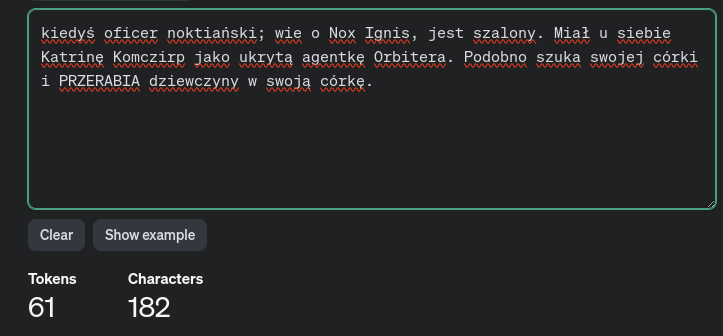
Czyli by zużyć 1000 tokenów kontekstu, możemy podać nawet 15 takich rekordów (oczywiście, gdyby dane były po angielsku to zajmowałyby mniej tokenów).
Strategie chunkowania:
- Jeśli mamy ustrukturyzowany tekst, gdzie możemy zamknąć myśli w sekcje, dzielimy po sekcjach
- Jeśli mamy tekst, w którym mamy luźne zdania / rekordy w bazie, dzielimy po tych rekordach / zdaniach
- Jeśli mamy tekst całkowicie losowo porozrzucany, wpierw warto zgrupować dane (np. przez clustering) a potem podać z tego podzbioru odpowiednie fragmenty
Jako, że to są dość ustrukturyzowane artykuły, warto podzielić po sekcjach. A - z ciekawości - jak by wyglądał podział na zdania?
Wykorzystamy do tego bibliotekę spaCy.
5.2. Implementacja #
5.2.1. Uczytelnienie kodu #
Ten kod zaczyna się robić coraz mniej czytelny przez to, że jest w jednym skrypcie. To sprawia, że w desperacji (by to dalej był jeden plik) wykorzystuję odpowiednik notacji węgierskiej:
- prefix 's0x__' oznacza krok do którego należy ta funkcja.
- Tak, nie jestem z tego dumny, ale jest to lepsze niż alternatywy.
- ...chyba że alternatywą byłby system kontroli wersji...
Oki, chodźmy do konkretów. SpaCy wykorzystamy w miejscu podziału tekstu na kawałki, czyli tutaj:
parsed_texts = _s01__extract_text_from_urls(links)
sections = _s01__cut_into_sections(parsed_texts) # <-- Ta linijka5.2.2. Ekstrakcja metody tnącej do cut_into_sections #
Sposób wyciągania sekcji z tekstu jest w tej chwili dość usztywniony; doprowadźmy to do działania, by móc dodać inną funkcję tnącą:
parsed_texts = _s01__extract_text_from_urls(links)
sections = _s01__cut_into_chunks(parsed_texts=parsed_texts, cutter_function=_extract_mkdn_sections)I teraz implementacja wygląda tak; jak widzicie, niewiele się zmieniło. To tylko lekka refaktoryzacja, ale odblokowująca nam inny sposób ekstrakcji (nowa funkcja, extract_sentences):
def _s01__cut_into_chunks(parsed_texts: list[str], cutter_function) -> list[str]:
all_chunks = []
for text in parsed_texts:
chunks = cutter_function(text)
all_chunks.extend(chunks)
return all_chunks
def _extract_mkdn_sections(text: str):
# Ten regex działa tak:
# dzielimy po h1-h4 ('#' - '####'); '#' to h1, '##' to h2...
# następnie ?= oznacza lookahead; czyli tak długo dodaje do grupy którą dzieli aż się pojawi kolejny nagłówek lub \Z, czyli koniec pliku / tekstu
pattern = r'(#{1,4} .+?)(?=\n#{1,4} |\Z)'
chunks = re.findall(pattern, text, re.DOTALL)
return chunks
def _extract_sentences(text: str):
pass5.2.3. Implementacja nowej metody tnącej po zdaniach przy użyciu spaCy #
Do dobrego dzielenia tekstu na zdania i "sensowne kawałki" warto wykorzystać bibliotekę spaCy. Fajna biblioteka z dobrą dokumentacją.
SpaCy wykorzystuje własne modele językowe odpowiedzialne za prawidłowy podział na zdania (owszem, można zrobić to regexem apokalipsy, ale serio odradzam; to jeden z tych 400-linijkowych regexów).
A quickstart i sublink models dają prostą odpowiedź jak to zrobić:
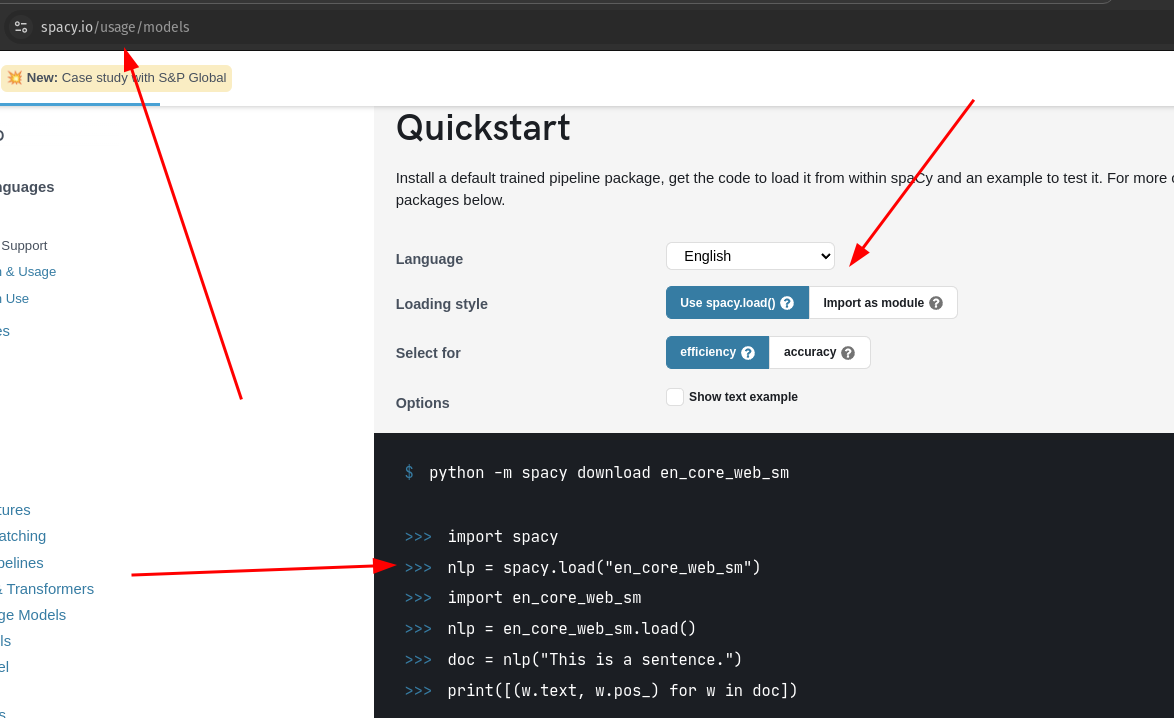
Więc najpierw instalujemy spaCy, dodajemy importa, ściągamy model
conda activate ollama
pip install spacy
python -m spacy download en_core_web_smA potem piszemy funkcję:
def _extract_sentences(text: str):
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
sentences = [sent.text for sent in doc.sents]
return sentencesI ją przepinamy jako strategię w kroku 1:
parsed_texts = _s01__extract_text_from_urls(links)
sections = _s01__cut_into_chunks(parsed_texts=parsed_texts, cutter_function=_extract_sentences)Oraz zwiększamy ilość zwracanych rekordów z 5 sekcji do 30 zdań:
collection = vdb_client.get_collection(collection_name)
context = collection.query(query_texts=[user_question], n_results=30)(oczywiście, w prawdziwym świecie mielibyśmy obiekt konfiguracyjny; dla strategii sekcji ustaw TAKĄ funkcję oraz TYLE zwrotów a dla strategii zdań ustaw TAKĄ funkcję oraz TYLE zwrotów; na potrzeby eksperymentu jest good enough)
Dla zwiększenia czytelności, zmieniłem prompt template by odpowiadał w krótkich bullet pointach; inaczej nie mam jak skopiować Wam odpowiedzi.
5.2.4. Wynik i wnioski z RAG z podziałem na zdania #

Jak widzicie, co prawda formatowanie jest nieco kiepskie, ale jest to ogólnie prawidłowa odpowiedź. A jakie dane otrzymał nasz RAG z Retrievera?
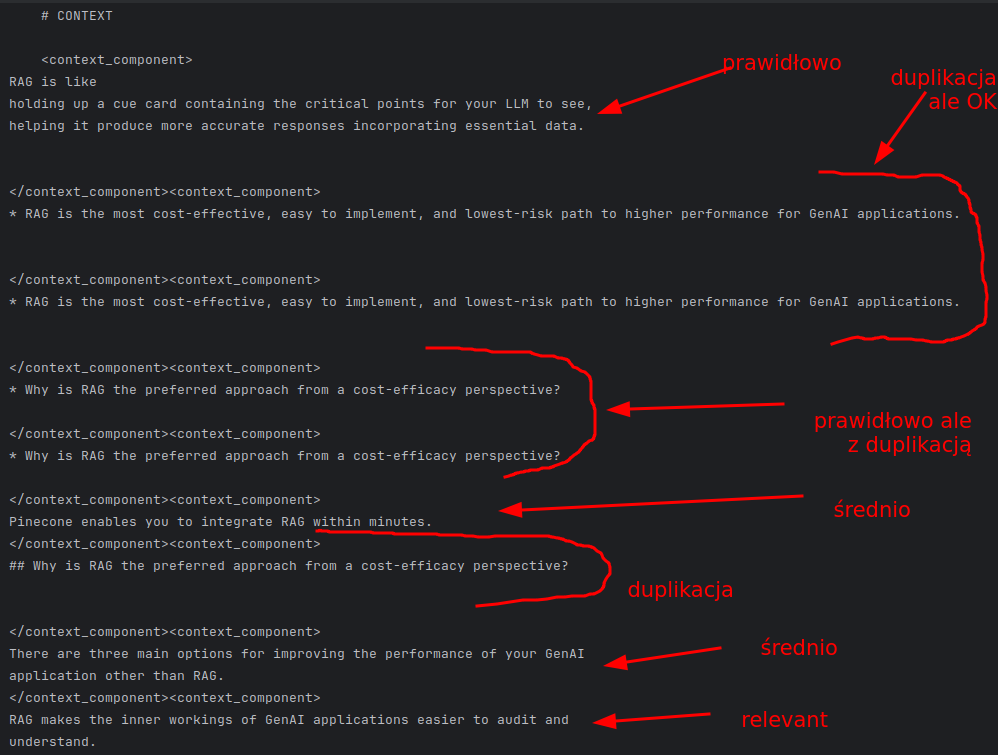
Gorzej.
Co możemy z tym zrobić?
- Możemy zrobić deduplikację na poziomie query; możemy tam usunąć rzeczy "zbyt podobne do siebie" używając embedding function
- Możemy lepiej spojrzeć na dane wejściowe i zapewnić, by już tam tego typu rzeczy się nie pojawiały
- Możemy wpierw podzielić na paragrafy/sekcje a potem podzielić te paragrafy/sekcje na zdania (a w metadanych zachować informację o tym, z jakiego paragrafu i dokumentu pochodzą). A potem podać zdanie i/lub paragraf/sekcję.
Oczywiście, wszystko zależy od danych wejściowych i od tego czego chcemy od tej aplikacji. Z mojej perspektywy, nie ma niczego czego chcę od tej aplikacji, więc nie mam jak testować jej pod kątem precyzji lub trafności. Nie na tym etapie.
Ale możliwości są.
5.2.5. Podział na zdania czy podział na sekcje? #
Chciałbym tylko zwrócić uwagę na ciekawą obserwację:
- Jeśli pytamy o coś "lokalnego", co w danych "będzie w sekcjach", podział na sekcje będzie lepszy.
- Jeśli pytamy o coś "nieciągłego", co może być poukrywane w różnych zdaniach, podział na zdania będzie lepszy.
Popatrzcie na tą różnicę; zadaję pytanie "Can Wardley maps help with implementing RAG in any way?":
Podział na SEKCJE, 5 sekcji na wejściu:

- Nie dostaliśmy ani jednego rekordu o mapach Wardley'a w Context
- Mamy sensowne i spójne odpowiedzi o RAG, bo dostaliśmy spójne sekcje
Podział na ZDANIA, 25 zdań na wejściu:

- Abstrahując od sensowności mojego pytania, mimo braku deduplikacji rekordów...
- Dostaliśmy zarówno informacje o RAG jak i mapach Wardley'a w Context
- Ale nie mamy tak "dobrych" informacji o RAG w Context jak mielibyśmy dla sekcji
5.2.6. To gdzie z tym idziemy? #
Potencjalnie moglibyśmy podejść do tego troszkę inaczej:

To jednak znaczy, że musimy podejść do tego wieloetapowo i LLM musi sam być w stanie podjąć pewne decyzje.
Z dobrych wieści - takie rzeczy da się zrobić. Nazywamy to Agentami.
Ale to opowieść na inny dzień.
6. Całość kodu wynikowego (skonfigurowany na sekcje) #
import html2text
import requests
import re
import chromadb
import openai
import spacy
# ========== MAIN FUNCTION TO RUN ==============
def run():
# 1. Acquire content to query
links = ["https://jxnl.co/writing/2024/05/22/what-is-prompt-optimization/",
"https://www.theuncertaintyproject.org/tools/wardley-maps",
"https://mattyyeung.github.io/deterministic-quoting",
"https://kenkantzer.com/lessons-after-a-half-billion-gpt-tokens/",
"https://www.pinecone.io/learn/retrieval-augmented-generation/"]
parsed_texts = _s01__extract_text_from_urls(links)
sections = _s01__cut_into_chunks(parsed_texts=parsed_texts, cutter_function=_extract_strat__mkdn_sections)
# 2. Embed content in vectorstore
collection_name = "llmAndStrategy"
vdb_client = _s02__embed_in_vectorstore(collection_name, sections)
# 3. Add local LLM
selected_llm = "phi3.5:3.8b-mini-instruct-q8_0"
#selected_llm = "gemma2:9b"
system_message_for_llm = "<|system|>\nYou are a helpful and concise assistant answering questions."
messages = [{"role": "system", "content": system_message_for_llm }]
llm_client = openai.OpenAI(base_url="http://localhost:11434/v1", api_key="nokeyneeded")
# 4. Main application loop
while True:
# 4.1. Get user question and exit the application
user_question = input("What is your question?")
if user_question == "exit":
break
# 4.2. Extract data from knowledge base (vectorstore)
collection = vdb_client.get_collection(collection_name)
context = collection.query(query_texts=[user_question], n_results=5)
# 4.3. Build an appropriate prompt from the template, question and context
prompt = _s04_3__create_prompt(user_question, context)
# 4.4. Pass prompt to LLM and get the answer
bot_response, messages = _s04_4__query_llm(llm_client, selected_llm, messages, prompt)
# 4.5. Display answer
print(_s04_5__format_answer_for_print(bot_response, context))
# ========== 4.5. Display answer ==============
def _s04_5__format_answer_for_print(bot_response, context):
return f"""# ANSWER
{bot_response}
# CONTEXT
{_aggregate_contexts_to_str(context)}
"""
# ========== 4.4. Pass prompt to LLM and get the answer ==========
def _s04_4__query_llm(llm_client, selected_llm, messages, prompt):
messages.append({"role": "user", "content": prompt})
response = llm_client.chat.completions.create(
model=selected_llm,
messages=messages,
temperature=0.2, # Low temperature to hallucinate less
max_tokens=400
)
bot_response = response.choices[0].message.content
messages.append({"role": "assistant", "content": bot_response})
return bot_response, messages
# ========== 4.3. Build an appropriate prompt from the template, question and context ==========
def _s04_3__create_prompt(user_question: str, context) -> str:
aggregated_context = _aggregate_contexts_to_str(context)
prompt = f"""<|user|>
<instruction>
Answer the question in short bullet points considering the context given. Some pieces of context will be relevant, some will not be.
Separate pieces of context are encapsulated in the xml tags '<context_component>'.
In case of no relevant information in the context at all, write "No relevant information in context".
</instruction>
<user_question>
{user_question}
</user_question>
Here's the context to assist you:
{aggregated_context}
<|assistant|>
"""
return prompt
def _aggregate_contexts_to_str(context):
opener = "<context_component>"
closer = "</context_component>"
aggregated_context = ""
for doc in context['documents'][0]:
aggregated_context += opener + "\n" + doc + "\n" + closer
return aggregated_context
# ========== 2. Embed content in vectorstore ==========
def _s02__embed_in_vectorstore(collection_name: str, sections: list[str]):
chroma_client = chromadb.Client()
collection = chroma_client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
ids = [f"id_{index}" for index, _ in enumerate(sections)]
collection.add(
documents=sections,
ids=ids
)
return chroma_client
# ============= 1. Acquire content to query =============
def _s01__cut_into_chunks(parsed_texts: list[str], cutter_function) -> list[str]:
all_chunks = []
for text in parsed_texts:
chunks = cutter_function(text)
all_chunks.extend(chunks)
return all_chunks
def _extract_strat__mkdn_sections(text: str):
# Ten regex działa tak:
# dzielimy po h1-h4 ('#' - '####'); '#' to h1, '##' to h2...
# następnie ?= oznacza lookahead; czyli tak długo dodaje do grupy którą dzieli aż się pojawi kolejny nagłówek lub \Z, czyli koniec pliku / tekstu
pattern = r'(#{1,4} .+?)(?=\n#{1,4} |\Z)'
chunks = re.findall(pattern, text, re.DOTALL)
return chunks
def _extract_strat__sentences(text: str):
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
sentences = [sent.text for sent in doc.sents]
return sentences
def _s01__extract_text_from_urls(urls: list[str]) -> list[str]:
all_texts = []
for url in urls:
response = requests.get(url)
if response.status_code == 200:
text = _extract_markdown_from_html(response)
all_texts.append(text)
return all_texts
def _extract_markdown_from_html(response):
converter = html2text.HTML2Text()
converter.ignore_links = True
text = converter.handle(response.text)
return text
# ============= EXECUTE THE CODE =============
run()
7. Wartościowe linki powiązane #
- https://jxnl.co/writing/2024/05/22/what-is-prompt-optimization/
- Jak programistycznie optymalizować prompta pod kątem swojego lokalnego LLMa
- ...i czemu to takie trudne
- https://mattyyeung.github.io/deterministic-quoting
- Jak zrobić pipeline RAG z odpowiedzią z Retrievera nie przechodzącą przez LLM by zredukować szanse na halucynację do 0
- "Tekst niebezpieczny" vs "tekst na pewno verbatim" - kolorowanie outputu
- Konkretne rady i procedury jak to zrobić. Poziom Design, nawet jak nie Implementacja.
- https://kenkantzer.com/lessons-after-a-half-billion-gpt-tokens/
- Seria praktycznych porad
- Lesson 1: When it comes to prompts, less is more.
- Lesson 2: You don’t need langchain. Just chat API.
- Lesson 3: Streaming API is a big UX innovation (users feel better).
- Lesson 4: GPT is really bad at producing the null hypothesis
- Lesson 5: “Context windows” are a misnomer; they grow for input not output
- Lesson 6: vector databases, and RAG/embeddings are mostly useless
- Lesson 7: Hallucination is strange; GPT doesnt make up variables but existence of standard library functions; doesn't know when to say "I don't know"